k-means法の可視化
授業用に作ったものを、こちらにも載せておく。
ちょっとした説明
今井. 2018. 『社会科学のためのデータ分析入門(上)』第3章に記載されている、DW-NOMINATEの1次元目及び2次元目のスコアを元に連邦下院議員を分類するタスクを扱う。分析の対象は第80議会 (1947-48)、クラスターの数はに設定する。
ここでは、アルゴリズムの挙動がよくわかるように、Rの標準関数であるkmeans() は用いず、各ステップが終了するごとにその時点での分類結果を図示するようにしている。
Rコード
# Load package require(tidyverse) # for alpha() function # Load & subset data url <- "https://raw.githubusercontent.com/kosukeimai/qss/master/MEASUREMENT/congress.csv" congress <- read.csv(url) congress.80 <- subset(congress, congress == 80) # k-means settings k <- 4 # number of clusters max.iter <- 100 # maximum number of iterations set.seed(1234) # Initialize congress.80$class <- sample(1:4, nrow(congress.80), replace = TRUE) congress.80$class.new <- NA plot(dwnom2 ~ dwnom1, data = congress.80, pch = 16, col = alpha(class + 1, 0.2), xlab = "DW-NOMINATE Score (1st dim)", ylab = "DW-NOMINATE Score (2nd dim)", main = "Iteration: 0") x.mean <- tapply(congress.80$dwnom1, congress.80$class, mean) # compute centroids y.mean <- tapply(congress.80$dwnom2, congress.80$class, mean) points(x.mean, y.mean, pch = 15, col = 2:5, cex = 1.5) for (i in 1:max.iter){ # Reassign each point to the nearest cluster for (j in 1:nrow(congress.80)){ # loop over legislators dist <- sqrt((congress.80$dwnom1[j] - x.mean)^2 + (congress.80$dwnom2[j] - y.mean)^2) congress.80$class.new[j] <- which(dist == min(dist)) } # Plot the current class assignments plot(dwnom2 ~ dwnom1, data = congress.80, pch = 16, col = alpha(class.new + 1, 0.2), xlab = "DW-NOMINATE Score (1st dim)", ylab = "DW-NOMINATE Score (2nd dim)", main = paste0("Iteration: ", i)) x.mean <- tapply(congress.80$dwnom1, congress.80$class.new, mean) # recompute centroids y.mean <- tapply(congress.80$dwnom2, congress.80$class.new, mean) points(x.mean, y.mean, pch = 15, col = 2:5, cex = 1.5) # break if class assignment doesn't change if (sum(congress.80$class != congress.80$class.new)== 0) break # update class assignment congress.80$class <- congress.80$class.new Sys.sleep(2) }
最後の行は、各時点における結果のプロットが一定時間以上表示されるようにするためのものである。
プロットに使う色が見にくい、ループを使うのは効率がよくない、といった問題はあるものの、一応動くから許容範囲かと…。
コードの実行結果をまとめたものが↓
10回目と11回目のループの結果が一致したため (つまりこの時点でアルゴリズムが収束) 、以下の図では、0回目から10回目の偶数回のループ後の結果を示している。

図を見ると、4回目のループ時点で、左側の観察群(すなわち、民主党議員)についてはほぼ完全に、右側(すなわち、共和党議員)についてもかなりの程度分類が完成していることがわかる。
結論:こういう研究に関係ないコード遊び (現実逃避?) は楽しい。
M+1法則の検証
人に見せる機会があったので、ここにも載せておく。
M+1法則とは
M+1法則とは、雑にいうと「定数Mの選挙区において、有力な候補者はM+1人になる」という、政治学の理論である。
Reed (1990) は単記非移譲式 (SNTV) による日本の衆議院議員選挙のデータを用い、候補者による学習により、経年的に有力な候補者の数がM+1に収れんしていっていることを明らかにした。
Cox (1994) は、ゲーム理論を用いて、有権者が戦略投票するとき、(i) 上位1-M番目の候補者 (当選者) の票数が等しくなり、(ii) 落選者の間では次点候補 (M+1番目の候補) のみが得票する、という均衡になることを示した。1
M+1法則の実証には、各選挙区の有効候補者数
を用いることが多い。ここで、は候補者
の選挙区における得票割合を、
は当該選挙区における候補者の数を表す。
これに対し、勝又 (2020) 2は、有効候補者数がM+1法則の実証にふさわしくない性質を持つことを指摘し、Cox (1994) の理論的な予測をよりストレートに検証するため、以下の2つの指標を使うことを提唱している。
具体的には、「上位1-M番目の候補者 (当選者) の票数が等しくなる」という予測についてはDEW3
という指標が、「落選者の間では次点候補 (M+1番目の候補) のみが得票する」という予測についてはDCR4
という指標が提案されている。実際の得票パターンがCox (1994) の予測にあっていれば、DEWは小さく、DCRは大きな数になるはずである。
実際にやってみる
ここでは、1993年以前の中選挙区制下における日本の衆議院議員選挙を例に、Reed (1990) や勝又 (2020) の結果をRを使って再現をしてみる。
選挙区レベルの選挙結果には、Reed-Smith Japanese House of Representatives Elections Datasetを利用する。
以下では、作図にはggplotを、それ以外の作業にはbase Rを使っている。
準備
# Load packages require(ggplot2) require(haven) require(patchwork) # Data reed.smith <- read_dta("./Reed-Smith-JHRED-CANDIDATES.dta") reed.smith <- reed.smith |> subset(byelection == 0 & !is.na(ku_m) & year <= 1993) reed.smith$ku_voteshare <- reed.smith$ku_vote / reed.smith$ku_totvote
データを読み込み、1993年以前の総選挙について、各選挙における各候補の得票率を計算しておく。
各指標の計算
years <- sort(unique(reed.smith$year)) enc.dat <- rep(NA, 6) for (i in 1:length(years)){ # loop over years # data for each election sub <- reed.smith |> subset(year == years[i]) dist.unique <- unique(sub$kuname) # compute ENC, DEW, & DCR for each district and store results res <- data.frame(district = dist.unique, year = years[i], magnitude = NA, enc = NA, dew = NA, dcr = NA) for (j in 1:length(dist.unique)){ # loop over districts tmp <- sub |> subset(kuname == dist.unique[j]) res$magnitude[j] <- tmp$ku_m[1] # district magnitude res$enc[j] <- 1 / (sum(tmp$ku_voteshare^2)) voteshare.m <- tmp$ku_voteshare[tmp$ku_rank == tmp$ku_m[1]] voteshare.w <- tmp$ku_voteshare[tmp$ku_rank <= tmp$ku_m[1]] # vote share of winners voteshare.r <- tmp$ku_voteshare[tmp$ku_rank == tmp$ku_m[1] + 1] # vote share of M+1th candidate voteshare.l <- tmp$ku_voteshare[tmp$ku_rank > tmp$ku_m[1]] # vote share of losers res$dew[j] <- sqrt(sum((voteshare.w - voteshare.m)^2) / (tmp$ku_m[1] - 1)) res$dcr[j] <- voteshare.r^2 / sum(voteshare.l^2) } enc.dat <- rbind.data.frame(enc.dat, res) } enc.dat <- enc.dat[-1,]
各選挙年の各選挙区について、ENC、 DEW、DCRを定義通り計算する。ループを使うのは効率がよくない (美しくない?) かもしれないが、これくらいのデータサイズであれば特に問題ない。
可視化する
まずはENCの経年的変化を、選挙区定数ごとにプロットする。
enc.dat$year2 <- substr(enc.dat$year, 3, 4) ## function for creating plots fun.plot.1 <- function(M, ylab){ tmp.plot <- ggplot(data = enc.dat |> subset(magnitude == M), aes(y = enc, x = factor(year2))) + geom_hline(yintercept = M + 1, color = "red", linetype = "dashed") + geom_boxplot() + ggtitle(paste0("M = ", M)) + xlab("") + ylab(ylab) + theme_bw() tmp.plot } g1 <- fun.plot.1(3, "Effective # of Candidates") g2 <- fun.plot.1(4, "") g3 <- fun.plot.1(5, "Effective # of Candidates") g.combined <- (g1 + g2) / (g3 + plot_spacer() + plot_layout(widths = c(1, 1.1))) + plot_annotation(title = "Testing M + 1 Rule under SNTV")
分布がよりクリアにわかるようにヴァイオリンプロットにしようかとも思ったが、1つ1つが小さくなりすぎてあまりきれいにならなかったので、箱ひげ図にした。
↓が出力された図。
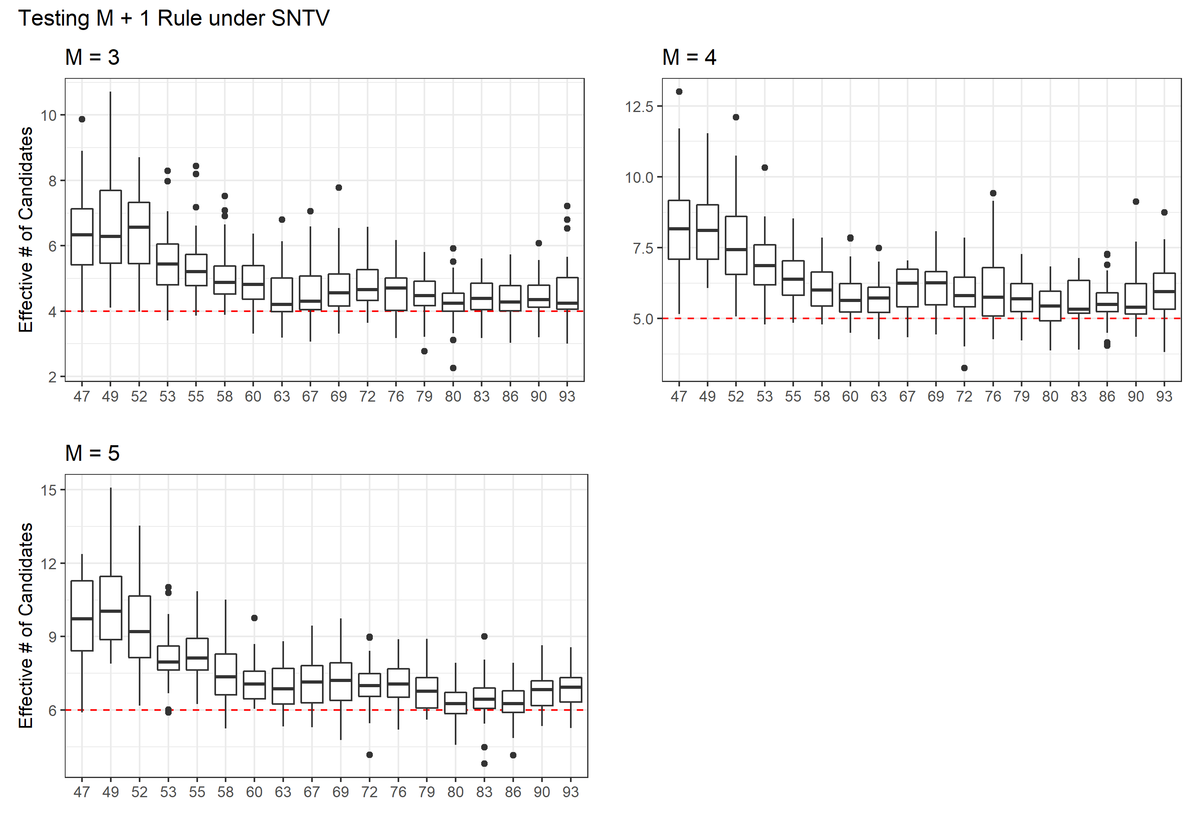 経年的に、有効候補者数がM+1に近づいていっていることがわかる。
経年的に、有効候補者数がM+1に近づいていっていることがわかる。
次に、DEWとDCRも可視化してみる。
これらの指標については、勝又 (2020) にならって、まず、各選挙における選挙区定数ごとの平均値を計算する。
katsumata <- matrix(NA, nrow = 3 * length(years), ncol = 3) katsumata[, 1] <- years colnames(katsumata) <- c("year", "dew", "dcr") for(i in 1:3){ # data for each M sub <- enc.dat |> subset(magnitude == i + 2) # compute mean DEW/DCR for each year katsumata[((i - 1) * length(years) + 1):(i * length(years)), 2] <- tapply(sub$dew, sub$year, mean) katsumata[((i - 1) * length(years) + 1):(i * length(years)), 3] <- tapply(sub$dcr, sub$year, mean) }
同じようにプロットする。
katsumata.df <- as.data.frame(katsumata) katsumata.df$year2 <- as.numeric(substr(katsumata.df$year, 3, 4)) katsumata.df$magnitude <- paste0("M = ", rep(c(3:5), each = length(years))) fun.plot.2 <- function(var.to.plot, title){ tmp.plot <- ggplot(data = katsumata.df, aes(x = year2, y = var.to.plot, shape = magnitude, color = magnitude)) + geom_point() + geom_line() + xlab("") + ylab("") + ggtitle(title) + theme_bw() + theme(legend.title = element_blank(), legend.justification = c(1, 0)) tmp.plot } g.dew <- fun.plot.2(eval(parse(text = "katsumata.df$dew")), "Degree of Equality among Winners (DEW)") g.dcr <- fun.plot.2(eval(parse(text = "katsumata.df$dcr")), "Degree of Concentration on Runner-ups (DCR)")
DEWの経年的な変化は↓
 次に、DCRのプロットが↓
次に、DCRのプロットが↓
 図から、(i) 当選者の得票数の分散は経年的に小さくなっておらず、むしろ1970年代以降大きくなっている、(ii) 1950年代以降落選者の得票は次点候補に集中する傾向が強まっているが、1980年代後半以降その傾向が弱くなっている、ことがわかる。
図から、(i) 当選者の得票数の分散は経年的に小さくなっておらず、むしろ1970年代以降大きくなっている、(ii) 1950年代以降落選者の得票は次点候補に集中する傾向が強まっているが、1980年代後半以降その傾向が弱くなっている、ことがわかる。
選挙区定数ごとの違いがわかりにくい図になっているけど、まあいいか。
おまけ
ということで、中選挙区時代の日本の衆議院議員選挙を例に、M+1法則に関する実証研究の再現をしてみた。
大雑把な結論としては、M+1法則はおおむね妥当だが、それなりに逸脱もある、という感じだろうか (適当すぎ…!?)。
ちなみに、作図した際にはDEWとDCRは平均値をとったが、当然選挙区ごとにばらつきがある。というよりも、これら2つの指標については、選挙区ごとの分散がかなり大きい。
例えば、1980年選挙における定数4の選挙区におけるDCRの分布を見てみると、
ggplot(data = enc.dat |> subset(magnitude == 4 & year == 1980), aes(x = dcr)) + geom_histogram(bins = 12) + xlab("") + ylab("") + theme_bw()
↓こんな感じになる。
 つまり、M+1法則の予想通り落選者の間で次点候補に票が集中している選挙区が多い一方、そうではない選挙区もそれなりにある。
つまり、M+1法則の予想通り落選者の間で次点候補に票が集中している選挙区が多い一方、そうではない選挙区もそれなりにある。
DEWやDCRの値を選挙区の特徴ごとに見ていくのも、日本政治研究的には面白いかもしれない。
頑健標準誤差 (robust standard error) を自力で計算する
RやStataといった統計ソフトでは、たいていの回帰モデルについて頑健な標準誤差 (robust standard error) を簡単に計算できる。
そのため、自力でrobust SEを求めなければいけないケースはほとんどない。
しかし、混合分布モデルなど複雑なモデルを用いる場合には、便利なコマンドが用意されていないこともある。
そこで、Rを用いて自分で計算できるよう備忘録として残しておこうと思う。
ちょっとだけ数式
Cameron and Trivedi (2005) の5.5.2節によると、パラメーターのrobust SEは
と表される。ここでの推定値にはヘシアン
が、の推定値には各観測点の勾配の積の期待値
が用いられる。および
は対数尤度関数を表す。
Rコード
ここでは二値変数を従属変数とするロジット/プロビットモデルを例として、上の式を実装してみる。
まず、以下が二値ロジット/プロビットモデルの尤度関数である。
# log lilekihood function llik.binary <- function(param, y, X, point = FALSE, cdf = plogis){ tmp <- cdf(X %*% param) llik <- y * log(tmp) + (1 - y) * log(1 - tmp) if (!point){ -1 * sum(llik) } else { llik } }
ここでpoint = TRUEとすることで、pointwise log likelihoodが計算できる。
また、cdf = pnormとすればプロビットモデルの対数尤度関数となる。
次に、以下が前節の数式を実装したものである。
require(numDeriv) # compute the robust variance-covariance matrix vcov.binary <- function(out, y, X, cluster = NULL){ N <- length(y) # number of observations K <- length(out$par) # number of parameters M <- NULL # number of unique clusters u <- matrix(NA, nrow = N, ncol = K) # Caluculating u for (i in 1:N){ u[i,] <- grad(func = llik.binary, x = out$par, y = y[i], X = X[i,], point = TRUE) } # for clustered SE if (!is.null(cluster)){ M <- length(unique(cluster)) u.clust <- matrix(NA, nrow = M, ncol = K) # Then adjust u for clustering for (j in 1:K){ u.clust[, j] <- tapply(u[, j], cluster, sum) } } # Then compute the robust vcov if (is.null(cluster)){ vcov <- solve(out$hessian)%*%((N / (N - 1))*t(u)%*%(u))%*%solve(out$hessian) } else { vcov <- solve(out$hessian)%*%((M / (M - 1))*t(u.clust)%*%(u.clust))%*%solve(out$hessian) } vcov }
勾配を計算するため、numDerivパッケージのgrad関数を用いる。
clusterにyと同じ長さのグループ変数を指定することで、clustered SEを計算することもできる。
また、Stataと近い結果を得るため、(N / (N - 1)) (もしくは(M / (M - 1))) をかけて調整している。
実データへの応用
ここではpsclパッケージ内にあるiraqVoteデータセットを用いる。
まず比較対象とするため、通常用いられる方法であるglm関数及びsandwichパッケージを利用し、回帰係数及びrobust SEを推定する。
> require(lmtest) > require(pscl) > require(sandwich) > out1 <- glm(y ~ rep + gorevote, data = iraqVote, family = binomial, x = TRUE) > coeftest(out1, vcovHC, type = "HC0") z test of coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) 5.878586 2.714224 2.1658 0.030323 * repTRUE 3.018809 1.052731 2.8676 0.004136 ** gorevote -0.113217 0.054421 -2.0804 0.037489 * --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
次に、前節で作った関数を用いて同じ分析を行う。
> out2 <- optim(rep(0, 3), llik.binary, y = iraqVote$y, X = out1$x, hessian = TRUE, + method = "BFGS") # coefficients > out2$par [1] 5.8774089 3.0188869 -0.1131937 # robust SE > sqrt(diag(vcov.binary(out2, y = iraqVote$y, X = out1$x))) [1] 2.72891380 1.05744123 0.05473097
glmを用いた分析とはやや数値が異なるが、これは最適化の誤差やアルゴリズムの差異に基づくものだろう。
最後に、この分析では必要ないが、州レベルでクラスター化した標準誤差も計算してみる。
まず、glmとsandwichを用いた結果が以下。
> coeftest(out1, vcovCL, cluster = ~ state.name) z test of coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) 5.87859 2.93595 2.0023 0.045255 * repTRUE 3.01881 1.06338 2.8389 0.004527 ** gorevote -0.11322 0.06005 -1.8854 0.059381 . --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
次に、前節の関数を用いた結果が↓。
> sqrt(diag(vcov.binary(out2, y = iraqVote$y, X = out1$x, + cluster = iraqVote$state.name))) [1] 2.93758429 1.06273594 0.06010004
こちらも結果の差異は誤差によるものと考えられる。
最近のできごと
「最近」とは何ヵ月前までを指すのかわからないけど…。
オンライン学会・研究会
今年の1月から5月上旬にかけて、Southern Political Science Association、Midwest Political Science Association、Asian Online Political Science Seminar、選挙学会とオンラインでの学会・研究会に参加してきた。
いずれも運がよく、報告に対して非常によいコメントをもらうことができた。
選挙学会では討論者も務めたが、他人の研究によいコメントができた…かどうかはわからない。
今後同様の機会があればまた頑張ろうと思う。
今まで対面の学会・研究会だと毎度ものすごく緊張していたのだが、オンラインだと自宅から気楽に参加できることもあり、そこまで緊張することなくリラックスして臨むことができた。
今後パンデミックが収束した後、私は対面の学会・研究会に戻れるのだろうか…。
インターネットがつながらなくなった
3月に契約しているwi-fiが突然つながらなくなる、という事件があった。
携帯のテザリングに頼りつづけるわけにもいかないのでComcastに連絡を試みた。
当初は電話番号が見つけられず、チャットに話しかけてみたものの、案の定 (?) 定型的な回答以外は理解してくれない。
電話番号を見つけられたのでかけてみたところ、最初につながったオペレーターの人は屋外からかけていたのか、背景音がうるさすぎてコミュニケーションにならず。
2回目につながったオペレーターの人とようやく会話ができ、翌朝技術者の人が家まで来てくれた。
どうやら自分の住んでいる地域でサービスのアップデートがあり、そのためモデムが対応しなくなっていたのが原因のようだった。
オペレーターの人と会話ができるまでかなり大変だった。まあこれもよい経験…ということにしておこう。
ワクチンを打った
4~5月にかけてコロナのワクチンを接種した。
1回目と2回目とで接種会場が違ったり、2回目の会場がとんでもない (?) 場所にあったりして大変だったが、久々の遠出で楽しかった。
ちなみに2回目の接種の後は翌日、翌々日と熱や倦怠感で使い物にならなかった。
定期的に接種しないといけない可能性もあるようなので、覚悟しておかないといけないと思う。
2回目接種の際のこと。
自分の番になって急にシステムが一時停止したため、待っている際に看護師の人と話した。
彼はベトナム出身で、フランス出身のいとこが現在日本に住んでいるらしい。
グローバルな家族だね、と言ったところ、戦争のせいでベトナムにいられなくなったから、と教えてくれた。
こういう悲しいことが再び起きないといいな、と強く思った。
世論調査は外れたのか?: 2020年アメリカ大統領選挙
今月初頭に行われたアメリカ大統領選挙において、4年前同様世論調査がトランプへの投票を過少に予測していたのではないかという指摘がされている。
英語ではそれなりに詳細な論考が出始めているが、日本語では (当然だが) 同様のものは見たことがない。
そこで、アメリカの世論を題材に博士論文を書こうとしている者として、自分の考えるところを少し記しておこうと思う。
世論調査は外れていた?
まず、接戦州における世論調査によるトランプへの支持と実際の得票率を比べてみる。
 上の表の1列目はEmerson Collegeによる選挙戦最終週の世論調査結果、隣の列はその標本誤差 (のようなもの) である。1
上の表の1列目はEmerson Collegeによる選挙戦最終週の世論調査結果、隣の列はその標本誤差 (のようなもの) である。1
表の3-4列目は、選挙戦最終週に各州でおこなわれた世論調査の重みづけ平均値及びその80%信頼区間である。2 世論調査の平均値を見るのは、仮に一つ一つの調査結果が外れていても、ズレが体系的でないならば複数の調査結果の平均値を見ることで真値に近い推定値を得られるからである。
最後に、表の5-7列目にはトランプの11月15日時点での実際の得票率及び世論調査による予測値との差をまとめた。3
上の表から、接戦州すべてでトランプの得票率が過小評価されていたことがわかる。多くは標本誤差内だが、接戦州すべてで得票を少なく見積もる確率はかなり低いので、何らかのバイアスがかかっている可能性が高い。
また、フロリダ、アイオワ、オハイオ、ウィスコンシンでは標本誤差を考慮しても世論調査結果と得票率との差が大きい。
以上から、残念ながら今回も世論調査は外れていたといわざるを得ないだろう。
なぜ世論調査は外れるのか
国勢調査などとは異なりすべての人から回答を得るわけではないため世論調査の結果は必然的に「外れている」わけだが、こうしたズレはサンプリングがきちんとした手続きにより行われているのであればどちらか一方に働くことはない。
では、なぜトランプへの支持が体系的に低く推定されたのだろうか?
メディアなどでは○○という集団の動向を捉えられなかった、などという説明がされることが多いが、ここではもう少し抽象的に方法上の問題を考えてみる。
非回答バイアス/回答者の偏り: 世論調査の回収率は近年非常に低くなっており、アメリカでは電話調査だと10%を下回ることが多い。また、選挙世論調査においても調査会社の登録者パネルのような便宜的なサンプルを用いることも多い。このような場合、世論調査に回答した人がそうでない人と比べ体系的に異なる意見を持っている可能性がある。
Likely Voter: アメリカの選挙世論調査では、投票する確率が高い有権者 (likely voter) における支持の分布に注目する。Likely voterの推定については様々な方法上の改善はされているだろうが、今回のように投票率が予想外に高い選挙においては誰が投票に行くかをうまく捉えれらない可能性がある。
投票先未定者: 有権者の中には投票日直前に誰に投票するかを決める人もいる。選挙前の世論調査は彼らの選好を捉えるのが難しい。
隠れトランプ支持: 世論調査回答者が社会的な望ましさなどの理由から真の選好を隠す場合がある。
選挙予測の副作用: これは調査方法自体の問題ではないが、世論調査や選挙予測の結果を見て投票行動を変化させる有権者がいる可能性がある(e.g., Rothschild and Malhotra 2014; Westwood et al. 2020) 。
上記の中で最も深刻なのは非回答バイアスだろう。投票先未定者については2016年の世論調査が外れた理由の一つと考えられている (AAPOR 2016) が、今回は投票先を決めていない世論調査回答者の割合が低かったことが指摘されている (Cohn 2020)。隠れトランプ支持については、リスト実験を用いた研究により否定的な結果が報告されていること (Coppock 2017)、またトランプが3年以上大統領を務めた後で彼への支持を隠す理由が薄いことなどから、あまり有力な説明とはいえないだろう。
補正の難しさ
世論調査結果がズレていても、事後的に補正できるのでばそれほど問題ではない。
非回答バイアスに対処するためには、ウェイトを用いることが多い。ただし、ウェイトによる補正は必ずしもうまくいくとは限らない。
Bailey (2019) によると、ウェイトによる補正は世論調査に回答するか否かが調査への (潜在的な) 回答内容と無関係である必要がある。4 例えば、若年層における世論調査の回収率は低くなる傾向がある。もし調査に回答した若者がそうでない若者と同じ程度トランプを支持しているのならば、ウェイトを使うことで非回答バイアスに対処できる。しかし、世論調査に回答してくれる若者は「変わった」人たちであり、調査に回答しない若者とトランプについて異なる意見を持っている可能性も高い。その場合、ウェイトを使うと「変わった」若者の重みを大きくすることでバイアスを強化してしまう危険性がある。
ではウェイトを使った補正がうまくいくのか、実際に見てみる。以下の表は今年の10月上旬から中旬にかけて行われたNPR/PBS NewsHour/Marist Pollの結果を示したものである。5

実際の選挙ではバイデンが51%弱、トランプが47%強の票を獲得していることを考えると、ウェイトをかけることでトランプへの得票がより過少に推定されてしまうことがわかる。
ウェイトによる補正の難しさは州レベルの世論調査においても同様である。最近行われた州レベルの調査の個票データが入手できなかったので、ここでは2016年の選挙前にフロリダ、ノースカロライナ、ペンシルヴァニアの各州で行われたNew York Times/Siena College Pollのデータを用いる。6 ウェイトはAmmerican Community Survey (ACS) 及びCurrent Population Survey (CPS) に基づき筆者が作成した。7

上の表を見ると、ウェイトをかけることですべての州でトランプへの支持が上方修正されているのがわかる。ただし、フロリダではトランプへの支持が過大に推定されてしまっている。また、ウェイトを用いてもペンシルヴァニアではトランプへの支持はクリントンへの支持よりも少ないままである。
ここで示したのは一例だが、調査回答者の偏りの事後補正がそれほど簡単ではないことがわかると思う。
ではどうしたらいい?
現在のところ非回答バイアスへの有効な対処法は残念ながらないように思われる。
ただし世論調査の質にかかわる問題なだけに、今後研究が発展していくことが予測される。
おそらく事後的な補正を可能にするため、何らかの方法で実験的に回答者に誘因を与えるような設計 (Bailey 2019はその一例) をする必要があるだろう。
いずれにせよ世論調査データを用いるものとして、注目していきたいと思う。
-
Emerson Collegeの世論調査を選んだのは、データの質に一定の評価があること、及び接戦州すべてで選挙戦最終週に調査を行っていたこと、の2点による。データはEmerson College Pollのホームページより取得した。なお、「のようなもの」と書いたのは、Emerson Collegeの調査は一部の回答者が通常の方法でサンプリングされておらず、代わりにAmazon’s Mechanical Turkを用いて集められているため、厳密な意味で標本誤差を計算することができないからである。↩
-
データはFiveThirtyEightの選挙予測特設サイトから取得した。FiveThirtyEightは世論調査のみならず失業率など他の要因も含めて選挙予測を行っているが、選挙戦最終週の予測は世論調査結果にのみ基づいていることから、FiveThirtyEightの予測値を世論調査の平均値として扱う。↩
-
選挙結果はDecision Desk HQのホームぺージより取得した。↩
-
Bailey, Michael. 2019. Designing Surveys to Account for Endogenous Non-Response. Unpublished Manuscript.↩
-
データはRoper CenterのiPollデータベースよりタウンロードした。↩
-
ウェイトの作成に当たっては、性別、年齢、人種、及び教育程度を考慮した。またACSとCPSのデータはIPUMS NHGISのサイトから入手した。↩
ICPSR Summer Program
ICPSR Summer Programは毎年ミシガン大学で行われる、社会科学で用いられる統計的手法に関するサマースクールである。
Summer Programのメインは6月下旬~7月中旬及び7月下旬~8月中旬に行われる4週間セッションなのだが、今年はコロナウイルスの影響でいずれもオンラインでの実施だった。
自分は今回縁あって前半のセッションでTAをやる機会に恵まれたので、いくつか感じたことや教訓 (?) をまとめておこうと思う。
その1. CPTに関して
アメリカでは留学生がICPSRのように自らの大学外で働くためには、CPTという特別な許可を得る必要がある。
CPTはビザ関係の手続きの中では非常に簡単な部類に入るのだが、やはりビザに関することなので手続きは早めにしておいた方がいい。
自分は今回恥ずかしながらギリギリになってからCPTを取らねばならないことを知ったので、周りの人に迷惑をかけてしまった。
昨今の就労・就学ビザに関する出来事もあるので、今後は気をつけようと思う。
その2. Zoom fatigue
オンラインでのミーティングやセミナーに伴う疲労をよく"Zoom fatigue"などと呼んだりする。
TAをやる前は、普段からパソコンばかり見ているから自分は大丈夫、などと思っていたが、実際にやってみると予想以上に大変だった。
平日は毎日講義とオフィスアワーを合わせて4-6時間Zoomしていたわけだが、それで消耗してしまってTA以外の勉強や研究はまるでできなかった。
コロナウイルスがしばらく収まらない可能性を考えると、こういったことにもなんとかして慣れないといけないなぁと思う。
その3. オンライン講義について
対面授業とオンライン授業とどちらがいいかについていろいろ議論がある。
オンライン授業のメリットとしてはチャットなどを使って受講者が質問しやすくなること、授業を録音すれば受講者が自分の都合の良い時間に勉強ができることが挙げられる。
他方対面授業と違ってオンライン講義だと受講者全体を見渡すことができないので、受講者がどの程度理解しているのかが非常にわかりづらかった。
また、Zoom fatigueもあってだと思うが、対面授業と比べドロップアウト率が高くなりがちなところも難しいなと感じた。
その4. StataとR
自分がTAをしていたコースではインストラクターの先生はStataを使って手法の実装について解説していたのだが、受講者の半数近くはRユーザーだった。
そのため自分はオフィスアワーや採点といったTAとしての通常の役割に加え、授業で用いられたStataコードをRに翻訳する、という仕事もしていた。
Stataはあまり見かけないようなモデルについても推定やその後の解釈に関するコマンドが用意されていて、さすが有料ソフト、非常に便利だと思った。
Rだと適切なパッケージがない場合自力で数式をコードに直さねばならないので、ある程度プログラミングや行列の扱いに慣れている必要がある。
そのため、Stataと比べてプログラミング初心者にはハードルが高いが、あまりわかっていない手法の実装が難しい、というメリットはあると感じた。
まあどちらも使えるのが一番なのだが…。
といろいろ書いたが、総じて非常によい経験だった。
夏休みの1か月をアナーバーで過ごせることを期待していたのでそれだけは心残りだが、アメリカ国内で移動できるようなったら避暑に行けたらと思う。
追記
先日のブログの主眼は後半部分のつもりだったが、どうやら前半部分のみがフィーチャーされて拡散されているようだ。
書いたものが筆者の意図と異なって理解されることは往々にしてあるので、そのこと自体は仕方のないことだと思う。
ただ、前半部分を取りあげる際に「ポリティカルコレクトネスの行きすぎの例」というような捉え方がされていることが多いようだが、個人的にはあまり正しくない解釈だと思う。
そこで、ここに前半部分について自分の考えることを少し書いておこうと思う。
まず、件のデータサイエンティストのツイートが問題化してしまったのは、「ポリティカルコレクトネス」の問題というよりも、アメリカにおける人種問題の根深さを反映していると捉えるべきだと思う。
ここで重要(だと私が考える)のは、Black Lives Matterを推進・支持する人でも運動の目標や戦略について必ずしも一致しているとは限らないこと、また件のデータサイエンティストが黒人ではなかった点だ。
前者についていうと、そもそもblack activist間で戦略や目標が違うのは今に始まったことではなく (例えばW.E.B. Du BoisとBooker T. Washingtonの論争)、昨今のBLM運動内部でも同様の対立が存在する。
そのため、「抗議活動に際して破壊は避けられない」という立場をとる人にとってはWasowの論文の結果は (政治信条に反するため) 受け入れにくいものだと思われる。
ただ今回問題がより大きくなったのは、おそらくWasowの論文の内容を紹介したのは白人だったからだろう。
あくまで反実仮想だが、同じツイートを黒人がした場合、論争にはなっただろうが、「人種差別主義者」であるという批判を受けることはなかったと思われる。
このような意味で、今回の出来事はアメリカの人種問題の難しいところが出てしまったものと捉えるべきだと考える。
また、事実関係が公表されていないのでわからないが、解雇に至った経緯も「政治的にincorrectな発言をしたから即解雇」というものではないと思われる。
彼が勤務していたデータコンサルティング会社はリベラル系の団体と取引のある会社なので、経営側としては取引先への影響力を考えたうえでの決定だったのだろう。
(「データコンサルティング」という企業の性質を考えるとその判断は賢明ではなかったと思うが)
しかし、「政治に関する科学的なコミュニケーションの難しさ」について書いたつもりのブログで、いきなりそれを痛感することになってしまった。
むむむ…。