M+1法則の検証
人に見せる機会があったので、ここにも載せておく。
M+1法則とは
M+1法則とは、雑にいうと「定数Mの選挙区において、有力な候補者はM+1人になる」という、政治学の理論である。
Reed (1990) は単記非移譲式 (SNTV) による日本の衆議院議員選挙のデータを用い、候補者による学習により、経年的に有力な候補者の数がM+1に収れんしていっていることを明らかにした。
Cox (1994) は、ゲーム理論を用いて、有権者が戦略投票するとき、(i) 上位1-M番目の候補者 (当選者) の票数が等しくなり、(ii) 落選者の間では次点候補 (M+1番目の候補) のみが得票する、という均衡になることを示した。1
M+1法則の実証には、各選挙区の有効候補者数
を用いることが多い。ここで、は候補者
の選挙区における得票割合を、
は当該選挙区における候補者の数を表す。
これに対し、勝又 (2020) 2は、有効候補者数がM+1法則の実証にふさわしくない性質を持つことを指摘し、Cox (1994) の理論的な予測をよりストレートに検証するため、以下の2つの指標を使うことを提唱している。
具体的には、「上位1-M番目の候補者 (当選者) の票数が等しくなる」という予測についてはDEW3
という指標が、「落選者の間では次点候補 (M+1番目の候補) のみが得票する」という予測についてはDCR4
という指標が提案されている。実際の得票パターンがCox (1994) の予測にあっていれば、DEWは小さく、DCRは大きな数になるはずである。
実際にやってみる
ここでは、1993年以前の中選挙区制下における日本の衆議院議員選挙を例に、Reed (1990) や勝又 (2020) の結果をRを使って再現をしてみる。
選挙区レベルの選挙結果には、Reed-Smith Japanese House of Representatives Elections Datasetを利用する。
以下では、作図にはggplotを、それ以外の作業にはbase Rを使っている。
準備
# Load packages require(ggplot2) require(haven) require(patchwork) # Data reed.smith <- read_dta("./Reed-Smith-JHRED-CANDIDATES.dta") reed.smith <- reed.smith |> subset(byelection == 0 & !is.na(ku_m) & year <= 1993) reed.smith$ku_voteshare <- reed.smith$ku_vote / reed.smith$ku_totvote
データを読み込み、1993年以前の総選挙について、各選挙における各候補の得票率を計算しておく。
各指標の計算
years <- sort(unique(reed.smith$year)) enc.dat <- rep(NA, 6) for (i in 1:length(years)){ # loop over years # data for each election sub <- reed.smith |> subset(year == years[i]) dist.unique <- unique(sub$kuname) # compute ENC, DEW, & DCR for each district and store results res <- data.frame(district = dist.unique, year = years[i], magnitude = NA, enc = NA, dew = NA, dcr = NA) for (j in 1:length(dist.unique)){ # loop over districts tmp <- sub |> subset(kuname == dist.unique[j]) res$magnitude[j] <- tmp$ku_m[1] # district magnitude res$enc[j] <- 1 / (sum(tmp$ku_voteshare^2)) voteshare.m <- tmp$ku_voteshare[tmp$ku_rank == tmp$ku_m[1]] voteshare.w <- tmp$ku_voteshare[tmp$ku_rank <= tmp$ku_m[1]] # vote share of winners voteshare.r <- tmp$ku_voteshare[tmp$ku_rank == tmp$ku_m[1] + 1] # vote share of M+1th candidate voteshare.l <- tmp$ku_voteshare[tmp$ku_rank > tmp$ku_m[1]] # vote share of losers res$dew[j] <- sqrt(sum((voteshare.w - voteshare.m)^2) / (tmp$ku_m[1] - 1)) res$dcr[j] <- voteshare.r^2 / sum(voteshare.l^2) } enc.dat <- rbind.data.frame(enc.dat, res) } enc.dat <- enc.dat[-1,]
各選挙年の各選挙区について、ENC、 DEW、DCRを定義通り計算する。ループを使うのは効率がよくない (美しくない?) かもしれないが、これくらいのデータサイズであれば特に問題ない。
可視化する
まずはENCの経年的変化を、選挙区定数ごとにプロットする。
enc.dat$year2 <- substr(enc.dat$year, 3, 4) ## function for creating plots fun.plot.1 <- function(M, ylab){ tmp.plot <- ggplot(data = enc.dat |> subset(magnitude == M), aes(y = enc, x = factor(year2))) + geom_hline(yintercept = M + 1, color = "red", linetype = "dashed") + geom_boxplot() + ggtitle(paste0("M = ", M)) + xlab("") + ylab(ylab) + theme_bw() tmp.plot } g1 <- fun.plot.1(3, "Effective # of Candidates") g2 <- fun.plot.1(4, "") g3 <- fun.plot.1(5, "Effective # of Candidates") g.combined <- (g1 + g2) / (g3 + plot_spacer() + plot_layout(widths = c(1, 1.1))) + plot_annotation(title = "Testing M + 1 Rule under SNTV")
分布がよりクリアにわかるようにヴァイオリンプロットにしようかとも思ったが、1つ1つが小さくなりすぎてあまりきれいにならなかったので、箱ひげ図にした。
↓が出力された図。
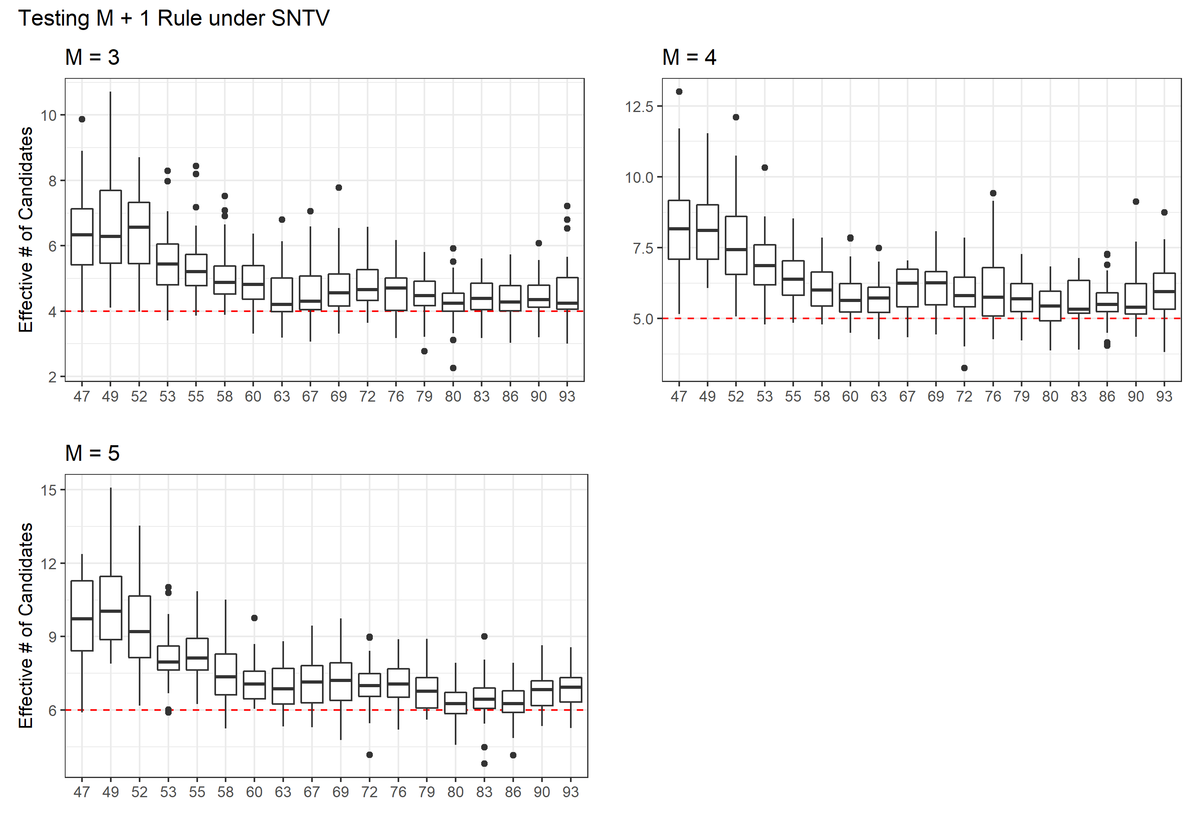 経年的に、有効候補者数がM+1に近づいていっていることがわかる。
経年的に、有効候補者数がM+1に近づいていっていることがわかる。
次に、DEWとDCRも可視化してみる。
これらの指標については、勝又 (2020) にならって、まず、各選挙における選挙区定数ごとの平均値を計算する。
katsumata <- matrix(NA, nrow = 3 * length(years), ncol = 3) katsumata[, 1] <- years colnames(katsumata) <- c("year", "dew", "dcr") for(i in 1:3){ # data for each M sub <- enc.dat |> subset(magnitude == i + 2) # compute mean DEW/DCR for each year katsumata[((i - 1) * length(years) + 1):(i * length(years)), 2] <- tapply(sub$dew, sub$year, mean) katsumata[((i - 1) * length(years) + 1):(i * length(years)), 3] <- tapply(sub$dcr, sub$year, mean) }
同じようにプロットする。
katsumata.df <- as.data.frame(katsumata) katsumata.df$year2 <- as.numeric(substr(katsumata.df$year, 3, 4)) katsumata.df$magnitude <- paste0("M = ", rep(c(3:5), each = length(years))) fun.plot.2 <- function(var.to.plot, title){ tmp.plot <- ggplot(data = katsumata.df, aes(x = year2, y = var.to.plot, shape = magnitude, color = magnitude)) + geom_point() + geom_line() + xlab("") + ylab("") + ggtitle(title) + theme_bw() + theme(legend.title = element_blank(), legend.justification = c(1, 0)) tmp.plot } g.dew <- fun.plot.2(eval(parse(text = "katsumata.df$dew")), "Degree of Equality among Winners (DEW)") g.dcr <- fun.plot.2(eval(parse(text = "katsumata.df$dcr")), "Degree of Concentration on Runner-ups (DCR)")
DEWの経年的な変化は↓
 次に、DCRのプロットが↓
次に、DCRのプロットが↓
 図から、(i) 当選者の得票数の分散は経年的に小さくなっておらず、むしろ1970年代以降大きくなっている、(ii) 1950年代以降落選者の得票は次点候補に集中する傾向が強まっているが、1980年代後半以降その傾向が弱くなっている、ことがわかる。
図から、(i) 当選者の得票数の分散は経年的に小さくなっておらず、むしろ1970年代以降大きくなっている、(ii) 1950年代以降落選者の得票は次点候補に集中する傾向が強まっているが、1980年代後半以降その傾向が弱くなっている、ことがわかる。
選挙区定数ごとの違いがわかりにくい図になっているけど、まあいいか。
おまけ
ということで、中選挙区時代の日本の衆議院議員選挙を例に、M+1法則に関する実証研究の再現をしてみた。
大雑把な結論としては、M+1法則はおおむね妥当だが、それなりに逸脱もある、という感じだろうか (適当すぎ…!?)。
ちなみに、作図した際にはDEWとDCRは平均値をとったが、当然選挙区ごとにばらつきがある。というよりも、これら2つの指標については、選挙区ごとの分散がかなり大きい。
例えば、1980年選挙における定数4の選挙区におけるDCRの分布を見てみると、
ggplot(data = enc.dat |> subset(magnitude == 4 & year == 1980), aes(x = dcr)) + geom_histogram(bins = 12) + xlab("") + ylab("") + theme_bw()
↓こんな感じになる。
 つまり、M+1法則の予想通り落選者の間で次点候補に票が集中している選挙区が多い一方、そうではない選挙区もそれなりにある。
つまり、M+1法則の予想通り落選者の間で次点候補に票が集中している選挙区が多い一方、そうではない選挙区もそれなりにある。
DEWやDCRの値を選挙区の特徴ごとに見ていくのも、日本政治研究的には面白いかもしれない。